それC++なら#defineじゃなくてもできるよ
この記事は 初心者 C++er Advent Calendar 2015 18日目の記事です.
17日目の記事は@yumetodoさんで C99からC++14を駆け抜けるC++講座でした.
はじめましての人ははじめまして, とさいぬです.
自称情報系の電気科学生をやっています.
C++歴は2年くらいで, Twitterで知り合ったC#erやRubyistのマネをしようとTwitterライブラリを書いたり, 最近は某所でプログラムを書きながら新しく入ったメンバーにC++を教えたりもしています.
もう汚いマクロは見たくないんだ
今年は何かと マクロ に苦しめられた年でした.
C言語の入門書や学校のC言語の授業では, #defineを 定数を定義するための構文 として細かな説明もなく使われだしたりします.
故に, 今年から参加することになった某所のソフトでは, こんなコードや
void yabai_func1() {
#define N 10
for (int i = 0; i < N; i++) {
/* */
}
}
void yabai_func2() {
#define N 15
for (int i = 0; i < N; i++) {
/* */
}
}こんなコードまで発掘されました.
class yabaclass {
private:
#define ARRAY_SIZE 10
// ...
};また, 昨年秋から今年の初めまで触っていたとあるフレームワークでは, 特殊な構文を実現するために定義された大量のマクロに起因する不可解なコンパイルエラー に悩まされ, C++やめてやろうかとまで思ったりもしました.
もうこんなマクロ定義するの, やめませんか?
そうした思いを込めて, この記事では Cプリプロセッサとは何か, そして C++だからできる#defineを使わない書き方 について紹介できたらなと思います.
Cプリプロセッサってなんだろう
C/C++のビルドプロセス
まず, C/C++のソースファイルを ビルド して実行ファイルが出来上がるまでの過程を再確認しておきましょう.
この ビルド と呼ばれる過程を簡単な図にすると以下のようになります.
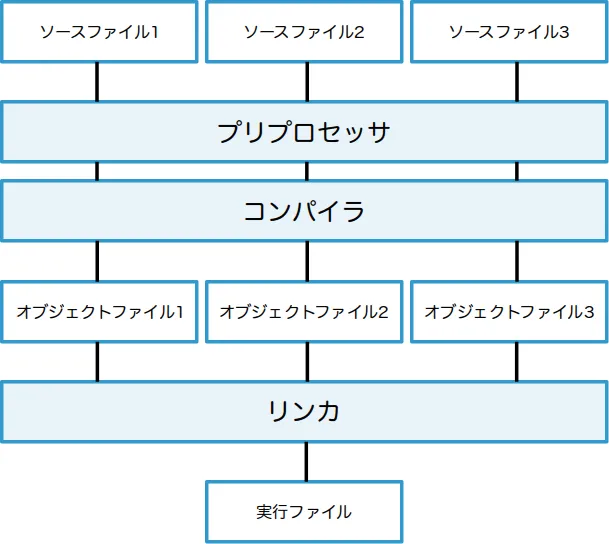
ソースファイルはまず プリプロセッサ によるコンパイル前の準備を受けます.
ここでは今回扱う#defineをはじめ, #includeや#ifdefといった#で始まる プリプロセッサ命令 が処理されます.
この段階を プリプロセス, プリプロセス時に行わせる処理を プリプロセス時処理 と呼んだりします.
プリプロセッサで処理されたソースファイルは コンパイラ が受け取り, コンピュータが実行できる形式, すなわち機械語への翻訳が行われます.
この段階を コンパイル, コンパイル時に行わせる処理を コンパイル時処理 と呼んだりします.
こうして出来上がったオブジェクトファイルは, リンカ によりまとめられ一つの実行ファイルになります.
図では省略していますが, 標準ライブラリとの結合もこの段階で行われます.
#define
先ほど説明したように, #defineを始めとするプリプロセッサ命令はコンパイルとは別の段階で処理されます.
では, 具体的に#defineはどのように処理されるのでしょうか.
ざっくり言うと, ソースファイルを テキスト文章 として扱い, #defineで定義されたマクロに従い 文字列の置換 が行われます.
例えばこんなコードがあったとします.
#define ARRAY_SIZE 10
int array[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; ++i) {
array[i] = i;
}このコードは, 1行目で定義されたマクロにより ARRAY_SIZEを10に置換する という処理がプリプロセッサで行われ, 以下のようなコードを生成しコンパイラに渡します.
int array[10];
for (int i = 0; i < 10; ++i) {
array[i] = i;
}プリプロセス時の処理は C++として ではなく テキスト文章として 処理されることが重要で, こんなコードも問題なく処理されますし…
#define START int main() {
#define PRINT(x) std::cout << x << std::endl;
#define END }
START
PRINT("Hello World!")
ENDスコープ といったC/C++の概念も存在しません.
void func1() {
#define ARRAY_SIZE 10
int array[ARRAY_SIZE];
// ...
}
void func2() {
int array[ARRAY_SIZE]; // ここでもARRAY_SIZEが使える
// ...
}今回は説明を省きますが, #includeと組み合わせれば… 置換が行われる範囲がヤバイことになるのは明らかですね.
この恐ろしさ, おわかりいただけただろうか…
C++だからできる #define を使わない書き方
定数
C言語では, 定数を宣言するための方法の一つとして#defineが使われてきました.
#define ARRAY_SIZE 10
int array[ARRAY_SIZE];こうした理由としては,
などがあります.
C++のconst
C++のconstはC言語と違い, const修飾されたオブジェクトは書き換えることはできません3.
また, 配列の要素数の指定に使うこともできますし, スコープの概念もちゃんとあります.
void nyan() {
const int array_size = 10;
int array1[array_size]; // OK!!
std::array<int, array_size> array2; // これも問題ない...?
}
void myon() {
int array[array_size]; // エラー, ここでarray_sizeは使えない
}#defineと違い, 型を明確にできるのもconstを使った定数の強みですね.
詳しい理由は省きますが, 多くのファイルからincludeされるようなヘッダファイルの#defineをconstに置き換える場合は, 多重定義などを防ぐためにstaticもつけると良いでしょう.
const static int i = 123;
const static double d = 4.56;
const static char c = 'A';
const static std::string s = "Nyan!";全てのクラスオブジェクトで使う定数を宣言したい場合もconst staticを使うと良いでしょう.
ただし, クラス定義の中で値を初期化できるConstant staticデータメンバはintもしくはenumの場合のみで, それ以外はクラス定義の外に定義を書かなければいけません. これは後述するconstexprを使うと解決できます.
class nyan {
// int, もしくはenumの場合のみ, クラス定義の中で初期化できる
const static int array_size = 10;
int array[array_size];
enum myon {
abc,
def
};
const static myon m = abc;
// それ以外は宣言しか書けず...
const static double d;
const static std::string str;
};
// ...クラス定義の外で定義を書かなければいけない
const double nyan::d = 1.23;
const std::string nyan::str = "Hello";constexpr変数
C++11からconstexpr指定子が追加されました. 1日目の記事で書かれているようにあまり初心者向けでなく, 僕自身使いこなせていない機能ではありますが, 今回のような用途に限定すれば極めて単純です.
変数を定義する際, constと同様にconstexprを付けることで, その変数は コンパイル時定数 となります.
コンパイル時定数, すなわち 配列の要素数の指定 や templateの非型引数 などにも渡すことのできる値を定義することができます.
もちろん, constと同じように実行時の定数としても扱えます.
constexpr int array_size = 123;
int array1[array_size];
std::array<int, array_size> array2;
std::cout << array_size << std::endl;全てのクラスオブジェクトで使う定数の宣言するとき, それがリテラル型(int, double, charなど)であればconstのかわりにconstexprを使うことができます.
constと違い, クラス定義の中で値を初期化することができるのは強いですね.
class nyan {
constexpr static int i = 1;
constexpr static double d = 1.2;
constexpr static char str[] = "nyan!";
};型に依らない関数モドキ
C言語では, MIN(), MAX()といった 引数の型に依らず動作する関数みたいなもの を定義するためにも#defineが使われてきました.
#define MIN(a,b) (((a)<(b))?(a):(b))
#define MAX(a,b) (((a)>(b))?(a):(b))
std::cout << MIN(12, 34) << std::endl; // => 12
std::cout << MAX(5.6, 7.8) << std::endl; // => 7.8関数template
昨日の記事でも取り上げられていましたが, もう一度.
C++では, 引数や返り値が違う同じ名前の関数を複数定義することが可能です.
これを 関数オーバーロード(多重定義)といいます.
int twice(int x) { // (1)
return x * 2;
}
double twice(double d) { // (2)
return d * 2;
}
std::cout << twice(12) << std::endl; // (1)が呼び出される. 出力は24
std::cout << twice(3.4) << std::endl; // (2)が呼び出される. 出力は6.8しかし, こうした関数を必要な型の数だけ書くのも大変だし, 関数の仕様変更の際は修正箇所が莫大に…
ってことで, それを半自動的に行うことができるのが 関数template でしたね.
template <typename T>
T twice(T n) {
return n * 2;
}
std::cout << twice<int>(12) << std::endl; // Tがintになった関数が呼び出される
std::cout << twice<double>(3.4) << std::endl; // Tがdoubleになった関数が呼び出される
std::cout << twice(12) << std::endl; // コンパイラがTはintだと推論してくれる
std::cout << twice(3.4) << std::endl; // コンパイラがTはdoubleだと推論してくれる関数templateを使えば, こうした複数の型に対応する関数を定義することが可能になるので, マクロを使った関数モドキは必要ありませんね.
上で挙げたMIN(), MAX()をtemplateを使って書き直すとこうなります.
template <typename T>
inline T min(T a, T b) {
return a < b ? a : b;
}
template <typename T>
inline T max(T a, T b) {
return a > b ? a : b;
}ちなみに, ここまで書いておいてなんですが, C++では<algorithm>ヘッダをincludeすることでstd::min(), std::max()が使えるようになります.
C++ならこちらを使うほうが良いでしょう.
まとめ
マクロは強力だけれど, C++ではある程度をC++だけで実現できます.
マクロは用法, 容量を守って正しく使い, バグの少ない, デバッグのしやすいプログラムを書いていきましょう!!!
参考文献
- C++ポケットリファレンス (2013) 高橋晶・安藤敏彦・一戸優介・楠田真矢・道化師・湯朝剛介 技術評論社
- C++11: Syntax and Feature (2013) 江添亮
- 中3女子でもわかる constexpr 村上原野
- static specifier - cppreference.com
Footnotes
-
ISO C99以降の規格ではconstでない変数でもブチ込めるらしいです http://en.cppreference.com/w/c/language/array#Variable-length_arrays ↩
-
const_castなんてなかった ↩